
We are extremely happy to announce that our research on “Human-centric emotion recognition in VR for Humanities research” has already been accepted for presentation at the 5TH CAA-GR CONFERENCE 2024.
Here is the abstract of this work:
In the rapidly evolving landscape of AI research, particularly within the realm of emotion recognition in immersive environments within challenging domains, such as social sciences and humanities research, the emergence of datasets like VREED has opened new avenues for exploration. VREED was recently published to accommodate research on emotion recognition, encompassing behavioral (eye tracking) and physiological signals, including electrocardiograms (ECG) and Galvanic Skin Responses (GSR), alongside self-reported responses from participants immersed in 360-Virtual Environments. Although accurate classification models can be achieved with this dataset, it is limited in sample size for the application of contemporary machine learning algorithms, such as Deep Neural Networks (DNN). This work introduces a new approach to address the inherent challenge of limited sample size when applying state-of-the-art machine learning techniques, such as DNN, to datasets like VREED. The proposed variation of the MixUp data augmentation method not only enhances dataset diversity but also fortifies the robustness of the models, providing a solution to the common issue of overfitting. The designed DNN architecture is meticulously crafted to capture intricate patterns in behavioral (eye tracking) and physiological signals (ECG and GSR) within VR environments. The findings of this work reveal substantial performance improvements compared to the baseline classifiers presented in the original VREED study, contributing significantly to the advancement of emotion recognition methodologies in VR settings relating to social sciences and humanities research.
The experiment was designed to evaluate the performance of various machine learning algorithms on three distinct classification tasks using the VREED dataset. The VREED dataset, known for its relevance in emotion recognition research, contains annotated data related to emotional valence, arousal levels, and the Circumplex Model of Affect (CMA) quadrants.
Three classification tasks were undertaken
- Arousal Classification: This task aimed to classify instances into high or low arousal categories.
- Valence Classification: Here, the goal was to categorize instances as having positive or negative emotional valence.
- CMA Quadrants (4-Class Classification): The CMA model divides emotional states into four quadrants based on valence and arousal dimensions, and this task involved classifying instances into these quadrants.
The authors of VREED initially employed Support Vector Machines (SVM) as the baseline classifier, drawing inspiration from prior literature. However, in this experiment, the researchers opted to explore the efficacy of alternative algorithms, including Decision Trees (DT), Random Forest (RF), XtraTrees (XT), and Multilayer Perceptron (MLP). Additionally, to potentially enhance model performance, the dataset was augmented using class intrinsic mixup, a technique aimed at generating additional training samples by blending existing instances.
Results and Analysis
Arousal Classification

- The SVM model from VREED achieved an accuracy of 0.9063 and an F1-score of 0.91.
- Among the experimented algorithms, XtraTrees (XT) and Multilayer Perceptron (MLP) yielded the highest accuracy and F1-scores (0.9375 and 0.9412, respectively), outperforming the baseline SVM.
- Decision Trees (DT) exhibited the lowest accuracy (0.78125) and F1-score (0.8108), indicating comparatively weaker performance in this task.
Valence Classification
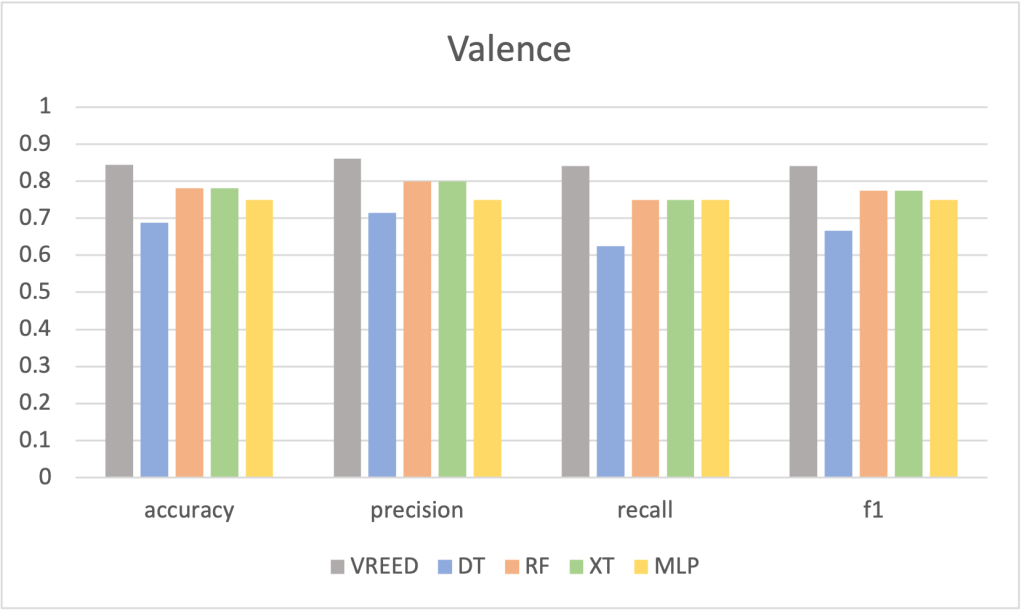
- The SVM baseline achieved an accuracy of 0.8438 and an F1-score of 0.84.
- XtraTrees (XT) and Random Forest (RF) demonstrated similar performance with accuracies of 0.78125, while Multilayer Perceptron (MLP) trailed slightly behind (accuracy of 0.75).
- Decision Trees (DT) again showed the lowest accuracy and F1-score (0.6875 and 0.6667, respectively) among the experimented algorithms.
CMA Quadrants (4-Class Classification)

- SVM achieved an accuracy of 0.7188 and an F1-score of 0.72.
- XtraTrees (XT) emerged as the top performer in this task with an accuracy of 0.84375 and an F1-score of 0.84375.
- Decision Trees (DT) exhibited the poorest performance, with an accuracy of 0.5 across all metrics.
The experiment demonstrated the effectiveness of alternative machine learning algorithms, such as XtraTrees (XT) and Multilayer Perceptron (MLP), in emotion classification tasks compared to the baseline SVM classifier. Additionally, the augmentation of the dataset with class intrinsic mixup appeared to have positively influenced model performance, particularly in scenarios where initial performance was suboptimal. This highlights the importance of sample size in machine learning tasks, where larger datasets enable models to capture more diverse patterns and generalize better to unseen data. Further research could explore additional augmentation strategies and ensemble techniques to enhance classification performance even further, while also considering the scalability and efficiency of such methods in real-world applications.